6 Must-Know Asian AI Models


Summary
- 70% of companies could integrate at least one form of AI, contributing $13 trillion to the global economy.
- DeepSeek has become the Chinese open-source alternative to LLaMA and Mistral.
- Hunyuan Turbo S is positioned as a “fast-thinking” model that can compete with DeepSeek, GPT-4o, and Claude 3.5.
- ERNIE 4.5 is claimed to surpass GPT-4.5 on multiple benchmarks while costing a small fraction ≈of 1% of GPT-4.5's cost.
- Kimi K2 is known for its ability to handle large amounts of text, starting with 200,000 characters and expanding to 2 million.
- Doubao-1.5-Pro is a new AI model created by ByteDance, the company that owns TikTok.
McKinsey forecasts that by 2030, 70% of companies could adopt at least one form of AI, such as computer vision, virtual assistants, or advanced machine learning, potentially contributing $13 trillion to the global economy and raising cumulative GDP by 16%.
In Asia, home to nearly 4.5 billion people, young generations are optimistic about AI’s impact on productivity, connectivity, and health, with relatively low concern about job loss. Globally, AI development is uneven, with the U.S. leading and China in second place. Of the estimated 22,400 top AI professionals worldwide, over 10,000 are in the U.S., and roughly 2,500 are in China.
Japan is applying AI to areas that complement its robotics expertise, creating models tailored to the Japanese language and to industries such as healthcare and manufacturing.
South Korea is using its strengths in technology and digital culture to develop AI models that are both advanced and consumer-friendly.
A key trend in Asia is the focus on adapting LLMs to local languages and industries. Unlike many Western models that mainly focus on English, Asian models are trained on large datasets in Chinese, Japanese, Korean, and other regional languages. They are also designed for specific industries, such as e-commerce, fintech, and education, making them highly relevant for real-world business use.
However, AI adoption is still in its infancy in Southeast Asia, according to the research.
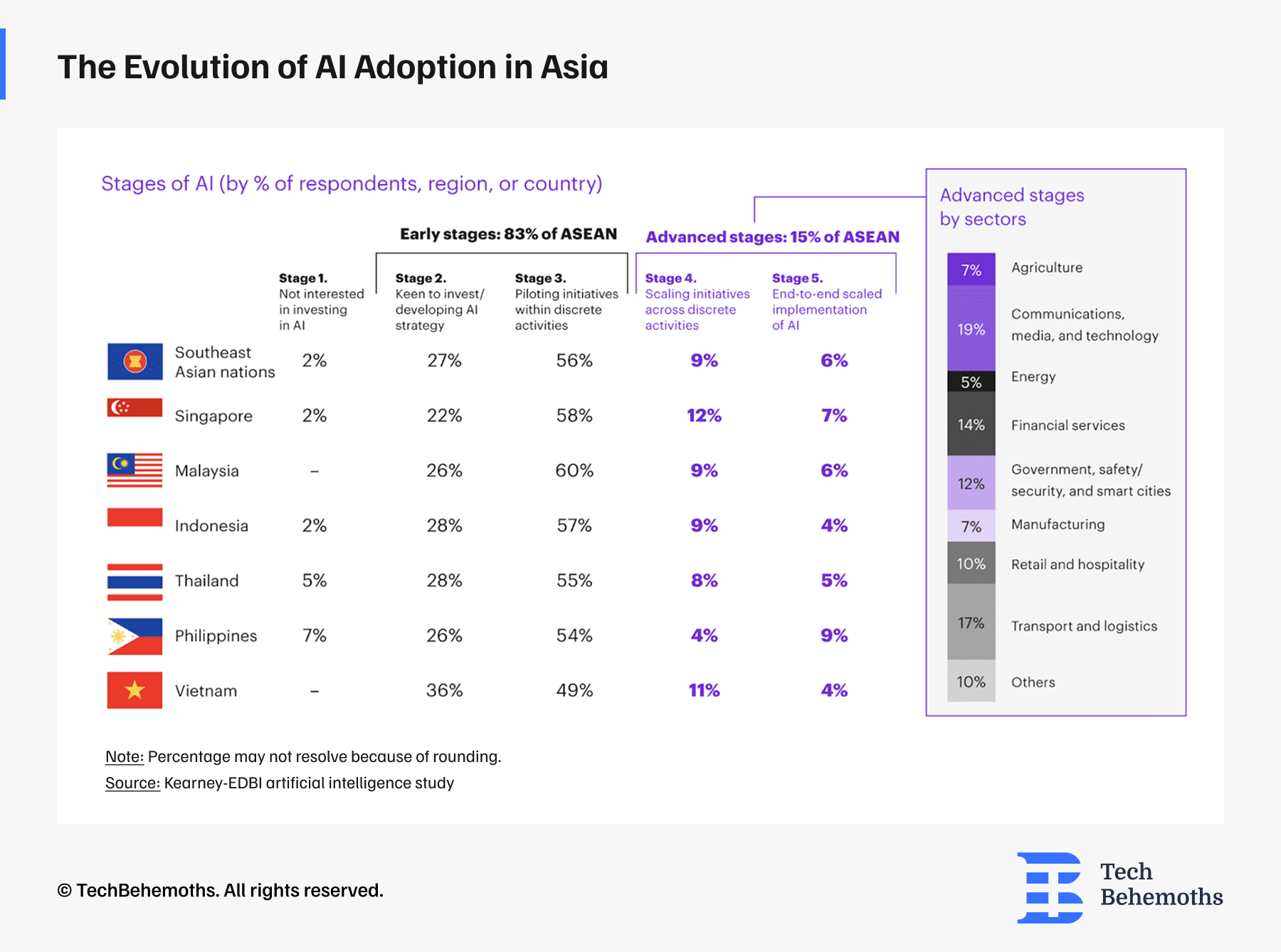
This article highlights six important AI models from Asia that are similar in ambition and capability to DeepSeek.
DeepSeek

Release: 2023-2024
Origin: Hangzhou, China
DeepSeek is an AI development company located in Hangzhou, China. Liang Wenfeng, who graduated from Zhejiang University, founded the company in May 2023. Wenfeng also co-founded High-Flyer, a quantitative hedge fund in China that owns DeepSeek. Right now, DeepSeek works as an independent AI research lab under High-Flyer. The total funding and value of DeepSeek have not been shared publicly.
DeepSeek develops open-source language models (LLMs). The company launched its first model in November 2023 and has since created several versions through multiple updates. It gained worldwide recognition in January 2025 after releasing its R1 reasoning model. DeepSeek offers various services for its models, including a web interface, mobile app, and API access.
DeepSeek uses a technique called Mixture of Experts (MoE), which sets it apart from models like GPT-4 or Llama 3. Instead of activating the entire model for every task, DeepSeek engages only the specific sections needed, resulting in faster and more efficient performance while maintaining high accuracy. It functions like a team of specialists, with the right expert addressing each problem.
| Model | Release Date | Params/Context | Key Features |
|---|---|---|---|
| DeepSeek Coder | Nov 2023 | — | First open-source coding model |
| DeepSeek LLM | Dec 2023 | — | First general-purpose LLM |
| DeepSeek-V2 | May 2024 | — | Improved performance, lower training cost |
| DeepSeek-Coder-V2 | Jul 2024 | 236B / 128K | Advanced coding model |
| DeepSeek-V3 | Dec 2024 | 671B / 128K | Mixture-of-experts, broad tasks |
| DeepSeek-R1 | Jan 2025 | 671B / 128K | Advanced reasoning, competitor to OpenAI o1 |
| DeepSeek-R1-0528 | May 2025 | — / 128K | System prompts, JSON, function calling, deeper reasoning (23K avg tokens) |
| DeepSeek-R1-0528-Qwen3-8B | May 2025 | 8B | Lightweight distilled model, Qwen3-based |
| Janus-Pro-7B | Jan 2025 | 7B | Vision model (image understanding & generation) |
| DeepSeek-V3.1 | Aug 2025 | 840B / 128K | Hybrid dual-mode (thinking & non-thinking), enhanced tool use & agents |
Which key functionalities does Deepseek offer?
DeepSeek has become the Chinese open-source alternative to LLaMA and Mistral. It supports both general-purpose chat and code generation, and its mixture-of-experts architecture enables efficient scaling.
- Open-source models like DeepSeek-7B, DeepSeek-Coder, and DeepSeek-MoE (Mixture of Experts).
- Strong performance on both English and Chinese benchmarks.
- Notable for its transparency, with detailed documentation of training data and open weights.
Potential or reported limitations:
- Infrastructure requirements are relatively large, making it less available for small teams to run a full V3 instance efficiently.
- Safety concerns were shown on a security evaluation that identified significant vulnerabilities in DeepSeek models, including risks related to content generation in sensitive domains.
Users raised concerns about opaque data policies, with inputs and outputs potentially being used to improve its services.
Alibaba’s QWQ 32B

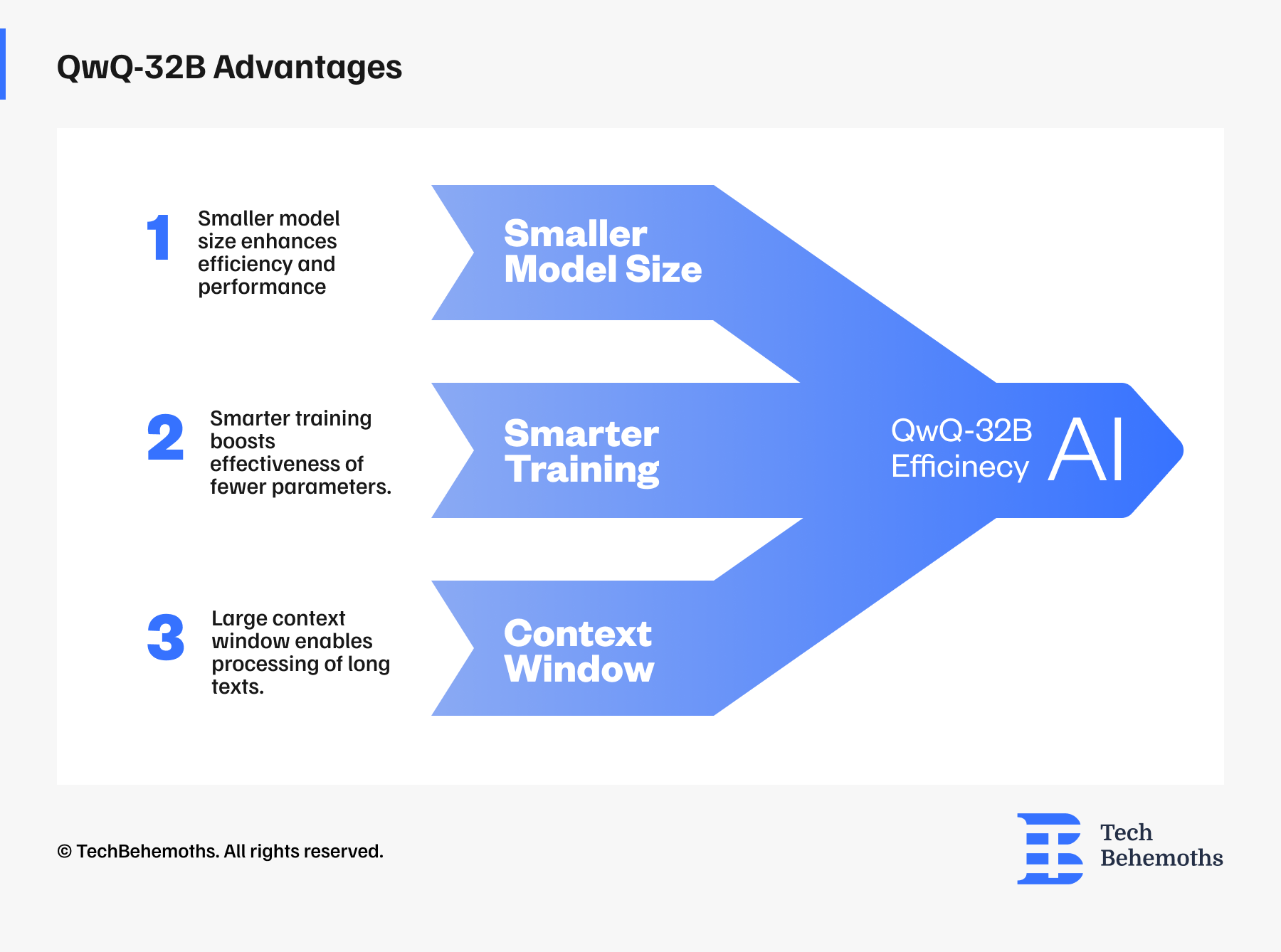
With the release of the Qwen-32B, a new model, Alibaba's Qwen Team has demonstrated its strength in the AI market. This model, which has 32 billion parameters instead of DeepSeek's 671 billion, performs almost as well as the industry-leading reasoning model, DeepSeek-R1.
The QwQ-32B is based on the previous QwQ-32B-Preview that we tested in this blog. Qwen has enhanced the reasoning abilities of the model with this final version and released it as open-source AI.
QwQ-32B is not a typical chatbot; it is a reasoning model. Most general-purpose AI models, such as GPT-4.5 or DeepSeek-V3, generate smooth, conversational text on various topics. In contrast, reasoning models focus on logically solving problems, analyzing steps, and providing clear answers.
Which key functionalities does QWQ 32B offer?
Math and logical reasoning - QwQ-32B is especially strong in solving math and logic problems. On the AIME24 benchmark, it nearly matched DeepSeek-R1, a model more than 20 times larger, and clearly outperformed OpenAI’s o1-mini. This shows that even though it’s smaller in size, it can keep up with much bigger models in accuracy.
Strong performance in reasoning tests - In IFEval, which checks how well a model can handle logical and symbolic reasoning, QwQ-32B scored higher than DeepSeek-R1 and came very close to the top score held by OpenAI’s o1-mini. This proves it can reason through structured problems, not just memorize answers.
Coding and software support - The model can write and refine code well. On coding benchmarks, it scored ahead of OpenAI’s o1-mini and close to DeepSeek-R1. Importantly, it doesn’t just generate code once—it improves its own answers step by step, which makes it more useful for real programming tasks.
General problem-solving - On LiveBench, which measures overall problem-solving skills, QwQ-32B performed slightly better than DeepSeek-R1 and far better than o1-mini. This highlights how smaller, optimized models can be as capable as huge proprietary ones when it comes to structured tasks.
Flexible and adaptive thinking - Perhaps its most impressive strength is functional reasoning—solving problems that require flexibility and adaptation. On the BFCL benchmark, QwQ-32B outperformed both DeepSeek-R1 and o1-mini. This suggests its training methods give it an edge in handling unfamiliar or complex problems where rigid models fall short.
Potential or reported limitations:
- This model can unexpectedly switch between languages, making responses less clear.
- QwQ-32B can sometimes get stuck in repetitive reasoning loops, leading to longer responses without a clear conclusion.
- Safety features should be improved in this model for enhanced reliability and security.
Hunyuan Turbo S (by Tencent)
.png)
Hunyuan Turbo S was released on February 27, 2025. It is positioned as a “fast-thinking” model that can compete with DeepSeek, GPT-4o, and Claude 3.5. This AI model works by combining two human cognitive processes - slow and fast thinking- for enhancing response efficiency and reasoning depth.
Turbo S leverages two robust frameworks: Mamba (suited for long sequences) and Transformer (contextual understanding). This mix is allowing it to prioritize speed and efficiency without neglecting performance. Additionally, this helps Turbo S to compete with models like Deepseek V3 and GPT-4o, and even outperform them.
Influencing the Chinese focus on AI leadership, Turbo S is not only a move for global AI but is cost-friendly and accessible for everyone, including tech firms and developers.
What Are the Key Characteristics of Turbo S?
Fast and slow thinking - Turbo S is using an adaptive long-short chain-of-thought mechanism that allows it to choose between the two modes for answering questions. It outperforms models like GPT-4o and Claude 3.5 in reasoning-heavy tasks while focusing on speed.
Instant replies - Tencent claims the model can respond in under one second, in contrast to “slow thinking” models, including Deepseek V3 (which take more time for reasoning or complex tasks). The reply time of this AI model was cut in half, and the delay in the first word was limited by 44%.
Performance and abilities - In terms of performance, in domains like knowledge, mathematics, and reasoning, it is said to be on par with DeepSeek-V3, GPT-4o, and Claude. These performances are caused by the integrated hybrid infrastructure and its mechanism of long and short thinking chains.
Base model for future expansions - Turbo S, being the flagship model, will become the foundation for Tencent’s Hunyuan series of derivative models, providing skills for these models, including reasoning, long articles, and code. There is already a model based on Turbo S, called the T1 reasoning model.
Cost efficiency - Currently, users and organizations can use Tencent Cloud’s API to call Turbo S and try it free for one week. The input price of this AI model is 0.8 yuan or $0.112 per million tokens, and the output price is 2 yuan or $0.281 per million tokens, which is cheaper than both DeepSeek V3 (input: $0.28/ 1M tokenks, output: $1.12/ 1M tokens), and GPT-4o (input: $2.5/1M tokens, output: $10/1M tokens).
Potential or reported limitations:
- The details of the trade-off between speed vs deep reasoning/correctness haven’t been fully exposed in public benchmarks yet. (Fast responses sometimes risk shallower reasoning.)
- How well it generalizes to very complex or multi-step tasks is less clear in available reporting.
- Also, model size, context window, and how it handles multimodal inputs (if at all) are not detailed in all sources.
ERNIE 4.5 / ERNIE X1 (by Baidu)
.png)
ERNIE 4.5 and ERNIE X1 are advanced language models created by Baidu. ERNIE 4.5 is the latest foundation model, while ERNIE X1 specializes in deep reasoning and problem-solving. Both models launched in March 2025 and aim to be versatile and cost-effective. They compete with leading global AI companies like OpenAI and DeepSeek. ERNIE X1 offers similar performance to DeepSeek R1 but at a lower price. Users can access both models through Baidu's ERNIE Bot, which became free for individual users after the launch.
- ERNIE 4.5 is Baidu’s newest foundation multimodal model. It handles not just text but also images, audio, and video inputs. It is intended to improve understanding, generation, reasoning, and memory.
- ERNIE X1 is a reasoning model, also multimodal, designed to excel in deep thinking: planning, reflection, etc. Baidu claims it matches DeepSeek-R1 in overall reasoning performance, but at about half the cost.
Strengths / What distinguishes them:
High cost-performance ratio - ERNIE 4.5 is claimed to surpass GPT-4.5 on multiple benchmarks while costing a small fraction (≈1% of GPT-4.5's cost, according to some reports). It also delivers performance on par with DeepSeek R1 at only half the price.
Accessibility - Both models are made free for individual users through Baidu’s Ernie Bot. The company’s latest model, ERNIE 4.5, offers prices for input and output starting at RMB 0.004 or $0.00056 and RMB 0.016 or $0.00225 per thousand tokens. For ERNIE X1, prices range from input: $0.00028/ thousand token and output: $0.00113/thousand of tokens.
Multimodal capabilities - ability to understand images, video, etc., beyond just text. Also, improvements are claimed in tasks like Q&A, logical reasoning, and document/image understanding. ERNIE 4.5 is equipped with contextual awareness, making it possible to understand internet memes, satirical cartoons, and more. ERNIE X1 excels in Chinese knowledge Q&A, manuscript writing, literary creation, dialogue, and complex calculations.
Potential or reported weaknesses/caveats:
- Pricing claims are relative and depend heavily on what “cost” includes—training, inference, and infrastructure. Real-world operational costs may vary.
- Benchmarks are often proprietary or limited; in many sources, comparisons are to DeepSeek or internal benchmarks rather than fully open international leaderboards.
- As always with multimodal models, performance may vary sharply depending on input type (text vs image vs video) and domain. Details matter.
Kimi (Moonshot AI)
.png)
Kimi is an AI chatbot created by the Chinese startup Moonshot AI and was released on 16 November 2023. It is known for its ability to handle large amounts of text, starting with 200,000 characters and expanding to 2 million. Kimi has developed into a very powerful, open-source model named Kimi K2. This model has a trillion parameters and is skilled at doing tasks on its own, coding, and complex reasoning. Kimi K2 is now a strong competitor in the global AI market.
According to the social media post of Nathan Lambert from July 14, a researcher at the Allen Institute for AI, “K2 is the new best-available open model by a clear margin.” Kimi K2 was already vaulted to the top of the LMSYS Chatbot Arena leaderboard.
Kimi K2 has a total parameter count at the trillion scale; however, due to its MoE architecture, it can activate only 32 billion parameters at a time. It is open-source like DeepSeek, meaning that it can be downloaded for free and modified by researchers.
Which key functionalities does Kimi K2 offer?
Stronger tool-using intelligence - Kimi K2 Thinking supports 200-300 consecutive tool calls in a single reasoning session, acting, interleaving planning, verifying, and refining steps. Compared to DeepSeek-R1, it has a chain-of-thought reasoning but does not orchestrate multiple tools.
Strong benchmarks - K2 can outperform models like GPT-5 and Claude Sonnet 4.5 on major benchmarks at a fraction of the cost. These benchmarks include coding, mathematics, reasoning tasks, and “agentic” abilities (i.e., handling multi-step workflows, invoking tools, etc.). On LiveCodeBench, Kimi K2 achieved an accuracy of 53.7% compared to DeepSeek V3 with 46.9% and GPT 4.1 with 44.7%.
Open weight with possibilities for commercial use - Two versions are available from Kimi K2: Base and Instruct. The second mode is used as a chatbot for direct interaction with users. Both versions are partially open-source, meaning they are publicly accessible and open to continuous development. Companies like OpenAI, Google, and Anthropic provide their models only on a subscription and API basis.
Very long context window - Kimi K2 supports up to 128,000-tokens context, and the newer K2-0905 has up to 256,000 tokens. This model uses Multi-head Latent Attention (MLA) that optimizes long sequences. K2 has a competitive advantage in tasks requiring long context, long chains of reasoning, and tool orchestration compared to GPT-5, and Claude Sonnet 4.5.
Stable training at a very large scale - K2 was trained on a very large dataset equal to 15.5 trillion tokens. For this training, Kimi K2 uses a novel optimizer with a QK-clip mechanism that prevents attention logit explosion, leading to zero spikes during the entire training. This combination gives K2 more stability and is more attractive for research compared to DeepSeek V3.
Potential Weaknesses / Boundaries:
- Even though it’s very capable, there is always concern around “thinking” models vs “fast reaction” ones: for deep logical reasoning, chain-of-thought, etc., it depends on how good the post-training and RL phases are.
- Managing and integrating tool usage (web browsing, code execution, etc.) introduces complexity and potential for errors.
- In very domain-specific or highly creative tasks, performance may lag proprietary closed models that have massive resources or specific fine-tuning.
Doubao-1.5-Pro (by ByteDance)
.png)
Doubao-1.5-Pro is a new AI model created by ByteDance, the company that owns TikTok. It launched in January 2025 and is designed to handle visual, voice, and text tasks effectively. This model utilizes a specialized system called Mixture-of-Experts (MoE) to operate efficiently. It performs well in reasoning and coding tests while maintaining low costs. Its design allows it to compete with larger models like GPT-4 and Claude 3.5 Sonnet at a lower price.
This outstanding performance is due to its leverage of a sparse Mixture of Experts (MoE) architecture. It uses fewer resources by activating only parts of the model as needed and adjusting its performance based on the task. While high-performance, Doubao-1.5 is also cost-effective, several times cheaper than other AI models.
Additionally, Doubao-1.5-pro has a Deep Thinking mode that increases the reasoning capabilities and offers valuable insights for tasks requiring complex problem-solving, with possible application in several industries.
What are its features:
Context window - Doubao-1.5-pro integrated a system design for prefill-decode and attention-FFN tasks, enhancing throughput and minimizing latency. Its extended context window of 32,000 to 256,000 tokens allows this model to process long texts more efficiently. Thanks to this feature, Doubao-1.5-pro has become a helpful tool for applications like legal document analysis, customer service, and academic research.
Advanced features - Its “Deep Thinking” mode is useful for enhanced reasoning capabilities. It has increased transparency, allowing users to see its reasoning steps, increasing trust. Its reasoning skills are also said to match GPT-4o and outperform the earlier versions on benchmarks like AIME.
Good performance - on “professional” benchmarks suggests suitability for work/productivity use-cases, coding, reasoning, etc. In fields like knowledge, code, reasoning, and Chinese, Doubao-1.5 has higher indicators than Deepseek V3, GOT-4o, and Claude-3.5. Additionally, this model is a “sweet spot” in size vs performance: large enough to handle complex tasks, yet presumably more efficient / less resource-intensive than the very largest models.
App integration and accessibility - Given ByteDance’s user base and product ecosystem, Doubao-1.5-Pro may be well integrated into services (chatbots, content generation, etc.). Thanks to its MoE architecture, it stands as an alternative for resource-intensive models like GPT-4 and Claude, prioritizing affordability, and it influences other AI tools to become widely available.
Possible limitations:
- Less public detail on multimodality, long-context, or advanced reasoning / “thinking” vs reaction.
- Being not open-weight (or less open) may limit external scrutiny or adaptation by researchers.
- The trade‐off between computational cost, inference latency, and deployment scale is always a concern: large models, even with MoE, require infrastructure.
Evaluating these 6 models: QwQ-32B, Hunyuan Turbo S, ERNIE 4.5, ERNIE X1, Kimi K2, and Doubao-1.5-pro, some trends were observed, such as:
- Core model for further versions: ERNIE 4.5 and Turbo S.
- Large context windows: QWQ-32B, Kimi K2, and Doubao-1.5-pro supporting up to 256,000 tokens.
- Competitive benchmark performance: With every model surpassing at a specific benchmark, models like GPT-4o, Claude 3.5, and Sonnet 4.5.
- Affordability focus: Doubao-1.5-pro, Kimi K2, ERNIE 4.5, and Turbo S are pushing for accessible AI features for every user and company.
These AI models that match or even surpass GPT-4 or GPT-5, DeepSeek models, and Claude versions are not only increasing the chances for Asia to become a leader in this domain, but also to make AI available for everyone, from developers to big tech organisations.
| AI Model | Strong Feature |
|---|---|
| QwQ-32B |
|
| Hunyuan Turbo S |
|
| ERNIE 4.5 and ERNIE X1 |
|
| Kimi K2 |
|
| Doubao-1.5-pro |
|
Conclusion
With the increased demand and integration of Artificial Intelligence technologies, Asia comes as a strong rival for the USA with its AI models, including DeepSeek V3, QwQ-32B, Hunyuan Turbo S, ERNIE 4.5/ERNIE X1, Kimi K2, and Doubao-1.5.
They provide strong indicators of performance in benchmarks such as math, reasoning, knowledge, and Chinese, becoming useful tools for business operations like data analysis, risk management, Business Intelligence, and many more. Being relatively new to the AI landscape, their full potential is still unknown, but users can themselves try and leverage their benefits.
In the coming years, it is possible to outdo the U.S., but there are still some challenges to be overcome, such as talent retention, security risks, and global market competition. Despite that, Asia is emerging as a leader in the AI field, with new models and updated tools, and features.
Related Questions & Answers
How Does Language Specialization Affect the Value of These Asian Models Compared to Global Ones Like GPT-4?
When Does It Make Sense to Pick One of These Asian AI Models vs a Global Competitor?
Do these Asian AI models Pose Higher Safety Risks?
What Are the Typical Strengths of These Asian AI Models?
Creativity has always been at the heart of who I am, from my love of art to my passion for writing. As a professional, my mission is to inform, inspire, and persuade, helping brands form deeper connections with their audiences. For me, talent is only 1% of success – the rest comes from dedication, strategy, and continuous learning.
I am an enthusiastic Biomedical Engineering Researcher and love learning about various domains. One of the biggest treasures that we, people, have is knowledge because it's hard to achieve and it depends only on human will. And it can be shared with others, that's why I like to find something new and share it with the world.
Discover more TechBehemoths Insights
Learn practical tips and insights about IT Companies, how to find the right company for your projects.
Read the latest news about Market Trends and fresh Interviews.